AMD再战英伟达!全面对比AMD和英伟达的产品性能和价格
昨夜凌晨的 Advancing AI 2025现场,苏妈直接掏出 CDNA 4 架构 MI350X/ MI355X——
再顺带放出 MI400、Helios 机架、ROCm 7 全家桶,算是把“再战英伟达”五个字写得明明白白。

下面我按“性能、内存、成本、生态、路线图”五个维度,给大家简单梳一遍核心看点。
01、性能:算力拳拳到肉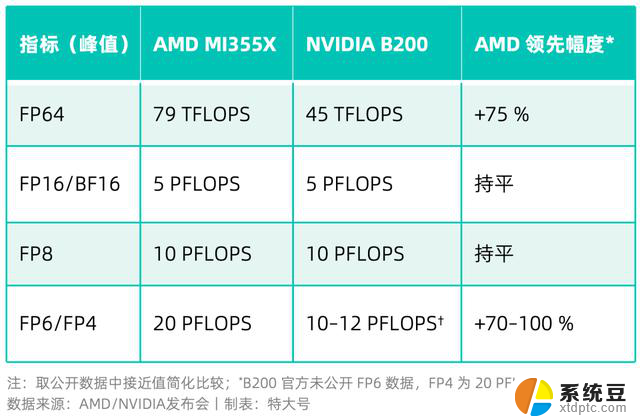
推理侧,在vLLM / SGLang 跑分里,MI355X 对 DeepSeek R1、Llama 3 70B 推理吞吐量比 B200 高约 20–30 % 。
训练侧,MI355X 预训练 Llama 3 70B(FP8)可跑出 MI300X 的 2.5–3.5 ×,与 B200/GB200 打成五五开 。
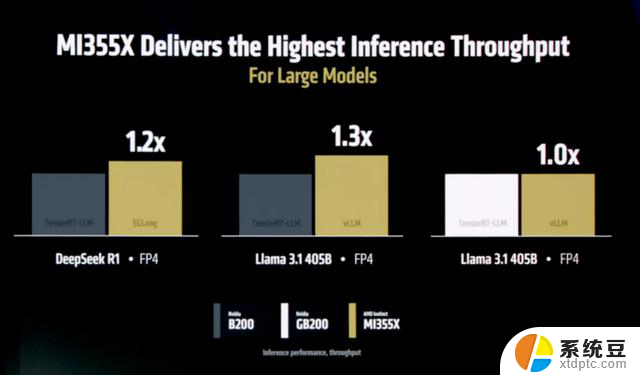
其实,看到“老外”测试举例采用DeepSeek,内心中还是有一些小触动。毕竟「国货」能被当成测试例的机会不多。
一句话:在当下流行的低精度 (FP8 以下)推理场景里,MI355X“更能打”。
02、内存:容量激增,带宽飙升
MI350系列内存容量 +60 %,内存带宽直上 8 TB/s。
HBM3E 288 GB 、8 TB/s,单卡就敢装下 520 B 模型,B200 只有 192 GB、6.1 TB/s。
卡间互联IF Link 1075 GB/s(8 卡互联),再次把 NVL4 的900 GB/s 刷到身后。
对超大模型/多实例推理来说,“HBM 多、带宽大”就是首要生产力。
 03、成本&能耗:按摩店老招牌
03、成本&能耗:按摩店老招牌AMD 宣称 “每刀 token 数量”比 B200 多 40 %,理由简单粗暴:
GPU 单卡价更低,同时288 GB HBM3E大显存,节约分片/分卡切分开销。
另外采用FP4/FP6 能让推理更高效,算力密度更好。

接着看能耗,而在 Perf/W 上,MI350X 相比 MI300X 又提升 30 % 。
换句话说,AMD 用“1000–1400W”功耗,跑出了与英伟达“GB200 2×1150W”同量级的推理成绩。
这对大规模集群的 TCO 影响,肉眼可见。
 04、生态:开源AMD vs 闭源英伟达
04、生态:开源AMD vs 闭源英伟达CUDA让人又恨又爱,你讨厌它却又不得不和它一起建设“社会主义”。
这就是闭源的痛,但AMD主导的ROCm是开源的——
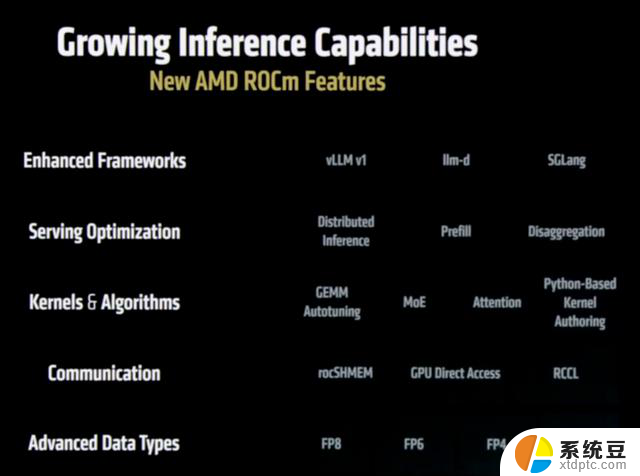
ROCm 7推理性能相对 ROCm 6 提升 3.5×,训练提速 3×;
Day-0 支持 Llama4、DeepSeek、Grok、Qwen 等主流模型(千问也被发了“好人卡”);
Windows 端和 Ryzen AI 本地开发也全家桶加持。
开源框架 vLLM / SGLang 与 AMD 同步联调,DeepSeek R1 的 FP8 推理,NVIDIA TensorRT-LLM 还不支持,AMD 先落地了。

这么说吧,“开源快过封闭” 是 AMD 给开发者的最大筹码。
05、路线图、大机架PK

主卡一年一代,一代更比一代强,MI400已经在路上了。
当然,“大机架”更能体现一个厂商的整体能力,这方面,AMD与英伟达可以一战,而老灯已经落伍了。

Helios 把 UALink + Ultra Ethernet 搭起来,号称横向带宽 260 TB/s,HBM4 容量比N家 Rubin 机架多 50 % 。
如今,AMD 把「CPU-GPU-DPU」全栈都握在自己手里,开始正面硬杠 NVIDIA 的 DGX 宇宙。
 06、流水不争先,争的是滔滔不绝
06、流水不争先,争的是滔滔不绝短期看,英伟达依旧握着整体性能优势、市场份额和CUDA护城河。
但 AMD 这次把 “更高性价比的算力+更大的显存+更开放的软件” 三张牌同步打出。
再加上 EPYC、Pensando、UALink 全家桶,MI350/400 显然有机会成为AI基建团队的新铲子。

接下来一年里,如果你在甲方采购需求里,看到 “288 GB HBM3E / FP4 20 PFLOPS” 字样,不用太惊讶——
那大概率是 AMD 再次把绿厂逼到了赛点。

“那个男人”压轴来捧场了,苏妈笑开了花。