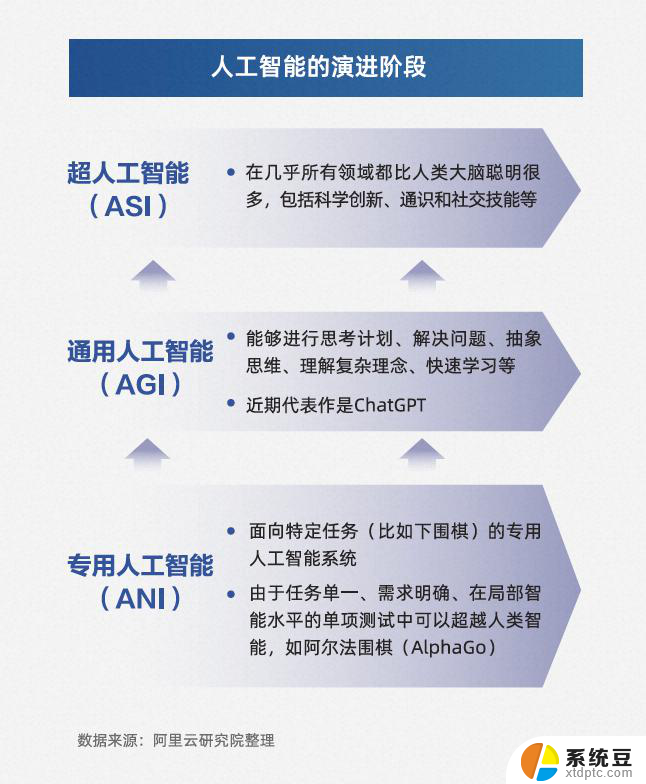
微软大模型:探索微软最新大型神经网络模型的特点与应用
更新时间:2024-01-16 18:17:38作者:xtdptc
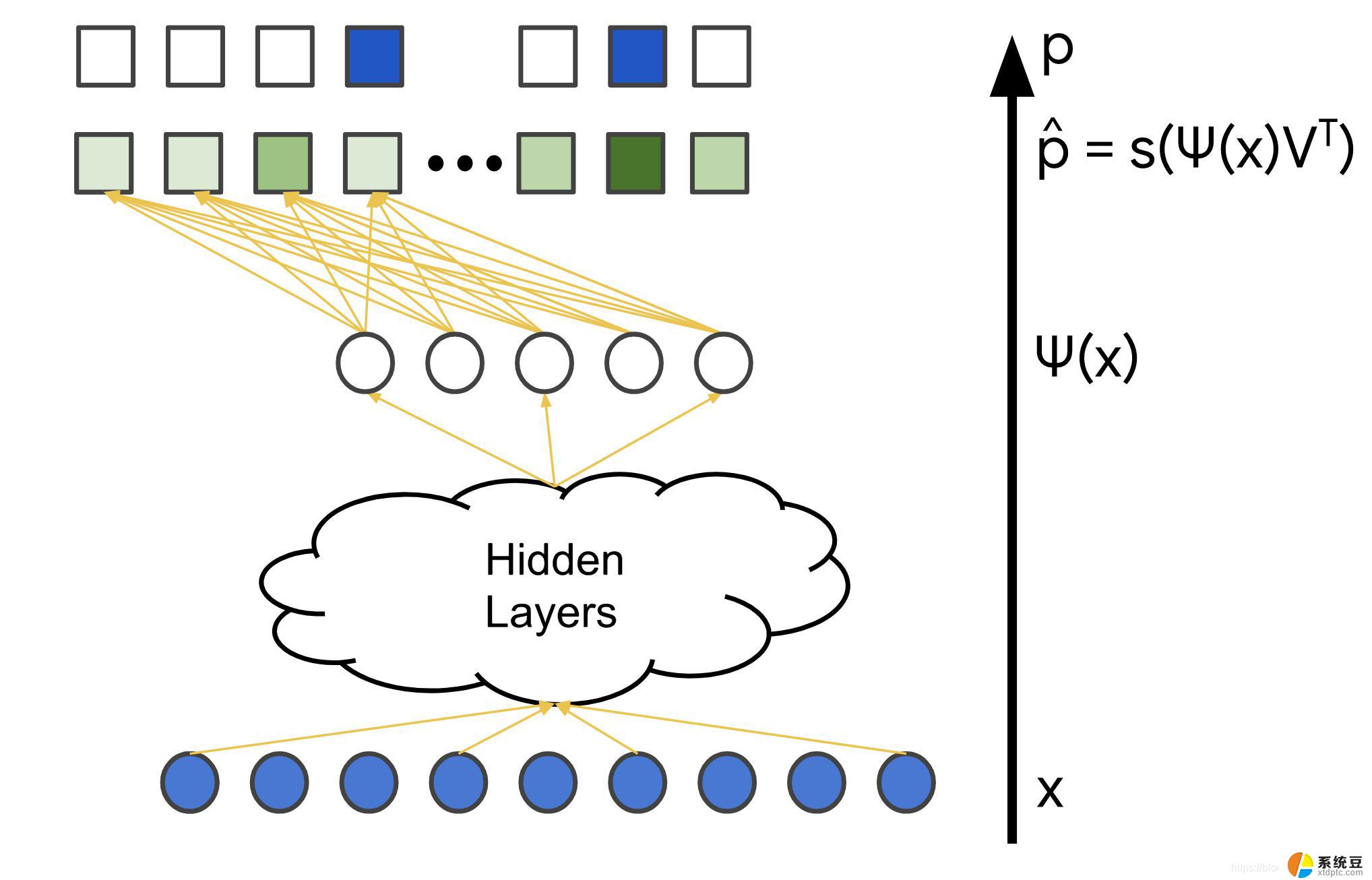
在自然语言处理领域,微软开发了诸如BERT、GPT和XLNet等大型预训练模型。这些模型通过在大量文本数据上进行预训练,学习到了丰富的词汇、语法和语义知识。在具体任务中,如文本分类、情感分析、信息抽取等。这些模型可以通过微调(fine-tuning)实现高性能表现。
在计算机视觉领域,微软开发了如ResNet、VGG和YOLO等大型深度学习模型。这些模型在图像分类、目标检测和语义分割等任务上取得了显著的成果,推动了计算机视觉领域的快速发展。
在语音识别领域,微软开发了如DeepSpeech等大型深度学习模型。这些模型通过学习大量语音信号的特征,实现了在语音识别和声纹识别等任务上的高性能表现。
微软大模型在各自领域具有较高的性能和广泛的应用价值。同时,微软也在不断更新和优化这些模型,以适应新的任务和数据集。在实际应用中,研究人员和工程师可以使用微软大模型作为基础,进行二次开发和优化,以解决具体问题。