英特尔第五代数据中心CPU、Guadi 3加速器细节曝光:性能突破巅峰,引领数据中心技术革新!
第五代 Emerald Rapids
英特尔的数据中心路线图仍在正轨上,第五代Emerald Rapids芯片定于12月14日发布。
英特尔介绍了旗舰级的64核Xeon 8592+与前代56核第四代Xeon 8480+相比的基准测试。和往常一样,对供应商提供的基准测试有所保留。
正如你所期望的那样,Xeon 8592+在AI语音识别和LAMMPS基准测试中获得了1.4倍的增益,同时在FFMPEG媒体转码工作负载中也获得了1.2倍的增益。

英特尔还为其未来的Granite Rapids Xeons提供了性能预测,该Xeons将在“英特尔3”节点上制造。这些芯片将为FP16添加更多的内核、更高的频率、硬件加速,并支持12个内存通道,包括大大提高内存吞吐量的新型MCR内存DIMM。总的来说,英特尔声称人工智能工作负载提高了2-3倍,内存吞吐量提高了2.8倍,DeepMD+LAMMPS人工智能推理工作负载提升了2.9倍。

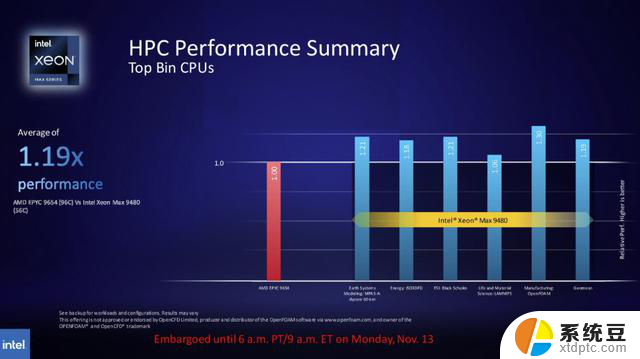
英特尔搭载HBM2E的Xeon Max CPU现已发货。英特尔将其配备64GB封装HBM内存的56核Intel Max 9480与AMD的96核EPYC 9654进行了比较。英特尔为这一系列基准测试选择的工作负载包括内存受限应用程序中的目标用例,这些用例自然会使至强芯片受益。总体而言,英特尔声称在模拟、能源、材料科学、制造和金融服务等一系列工作负载方面,其平均优势是EPYC竞争者的1.2倍。

Gaudi 3与Falcon Shores GPU
英特尔还分享了即将推出的Gaudi 3的一些细节,这将是该公司将Gaudi 和GPU系列合并为一个单一产品Falcon Shores之前的最后一款Gaudi加速器。
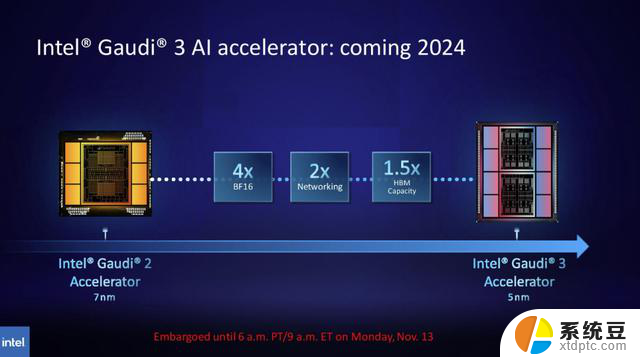
据介绍,Gaudi 3基于5nm工艺,在BF16工作负载方面的性能将是Gaudi 2的四倍,网络性能也将是其的两倍(Gaudi 2有24个内置的100 GbE RoCE Nic),HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。正如我们在图中所看到的,Gaudi 3转向了具有两个计算集群的基于chiplet的设计,而不是Intel为Gaudi 2使用的单芯片解决方案。
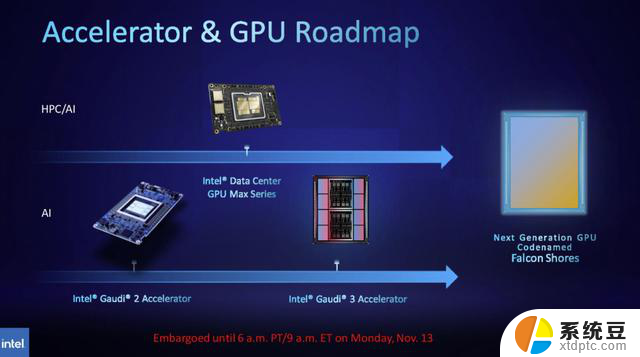


英特尔在提供其未来Falcon Shores GPU的细节方面进展缓慢。但英特尔表示,尽管合并了Habana Gaudi IP和Xe GPU IP的各个方面,但基于chiplet的Falcon Shores将通过OneAPI编程接口看起来和起到单个GPU的作用。Falcon Shores将采用HBM3内存和以太网交换,并支持CXL编程模型。此外,为Gaudi加速器和Xeon Max GPU调整的应用程序将与Falcon Shores前向兼容,从而为其客户提供两种截然不同的GPU和Gaudi系列之间的代码连续性。

数据中心GPU Max系列
英特尔的数据中心GPU Max系列目前正在向客户发货,Supermicro提供了带有八个OAM外形GPU的系统,而戴尔和联想则提供了四个OAM GPU服务器。GPU Max系列1100 PCIe卡也可从多个供应商处广泛获得。

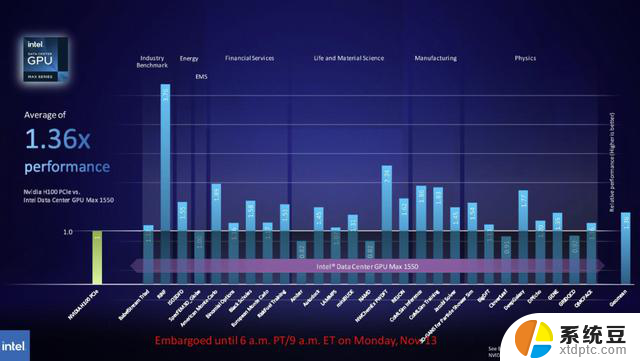
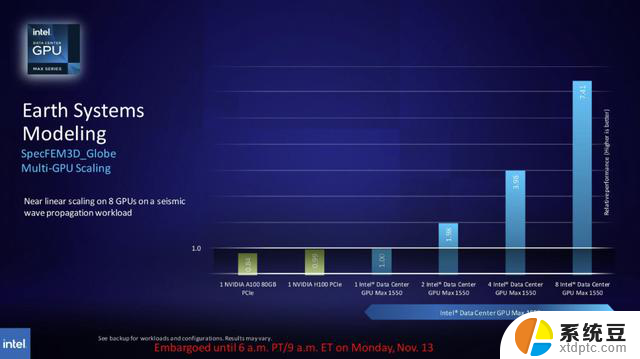
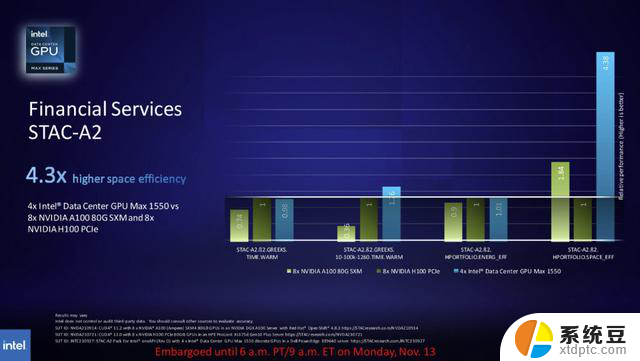
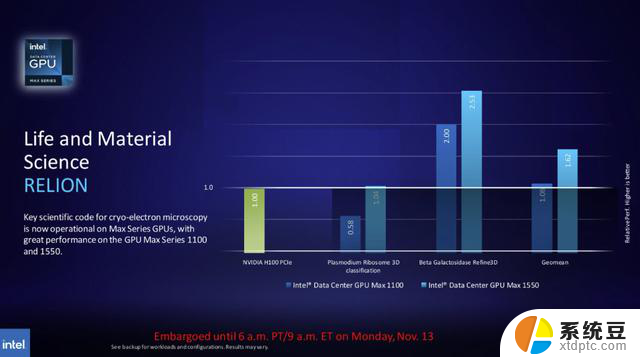
英特尔的基准测试将其600W GPU的OAM外形尺寸的Max 1550与350W竞争对手英伟达的PCIe外形尺寸H100进行了比较。英特尔指出,难以访问OAM形状因子H100 GPU是基准差异的原因。
Aurora 超级计算机
根据之前的预计,基于英特尔芯片的Aurora超级计算机 将以 2 Exaflop/s (EFlop/s) 的性能夺得世界上最快的超级计算机的桂冠。然而,英特尔尚未透露有关 Aurora 正式提交 Top500 名单的基准测试的详细信息,该公司表示将把该公告留给能源部和阿贡国家实验室。如果按照惯例,Top500 组织将在今天晚些时候发布这些备受期待的结果。与此同时,英特尔的更新包含了大量值得仔细研究的新新信息。
基于英特尔芯片的Aurora超级计算机的详细介绍:《全球首台200亿亿次超算安装完成:21248个CPU、63744个GPU、20.42PB内存、220PB存储!》

根据英特尔最新公布的数据显示,英特尔和阿贡国家实验室在genAI项目中测试了Aurora,这是一个万亿参数的GPT-3 LLM科学基础人工智能模型。由于数据中心GPU Max(“Ponte Vecchio”GPU)上存在大量内存,阿贡国家实验室在总共256个节点上并行运行了四个模型实例。在对工作负载进行调优后,此工作负载最终将扩展到10000个节点。

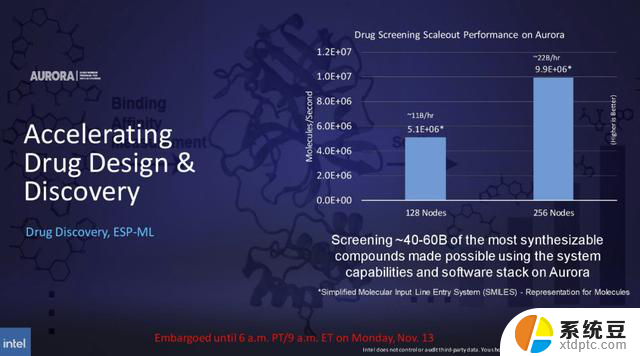
英特尔强调,在药物筛选人工智能推理应用程序ESP-ML中,从128个节点到256个节点的强大扩展能力。
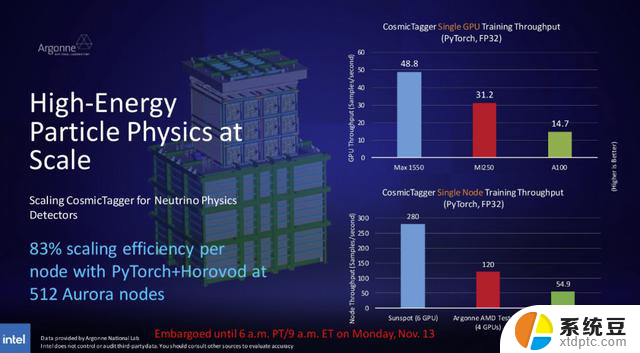
但与竞争对手GPU的对比更有趣。英特尔声称,在使用PyTorch/FP32进行CosmicTagger训练时,单个Max 1550 GPU的速度比AMD的MI250加速器提高了56%,比英伟达的上一代A100 GPU有2.3倍的优势。结果还表明了强大的可扩展性,六GPU Sunspot测试节点显示出83%的性能可扩展性。因此,Sunspot节点的性能是具有未知GPU的四GPU AMD测试系统的两倍多,是Polaris的四GPU节点的五倍多。
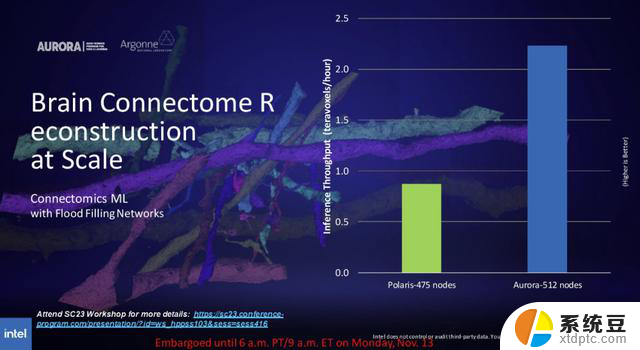
Argonne还测试了拥有512个节点的Aurora超算与475个节点的Polaris超算面向大脑连接体工作负载(Connectomics ML)能力,该工作负载模拟了小鼠的大脑。突出了Aurora相对于Polaris的2倍优势。

编辑:芯智讯-浪客剑 资料来源:tomshardware